

 ソニック
ソニックmatplotlibを進化させる、美しい可視化ライブラリ
「matplotlibのグラフは事務的すぎる」「もっと統計的な可視化を簡単にしたい」
そんな悩みを解決するのが、Pythonのライブラリ「seaborn(シーボーン)」です。matplotlibを進化させたデザインで、統計的なグラフを驚くほど簡単に作れます。
私自身、データサイエンス業務で顧客レポートを作る際、seabornを多用しています。同じデータでも、seabornを使うだけで「伝わるレポート」になります。
この記事では、seabornの基本から統計的なグラフ作成のテクニックまで、コピペで使えるコード付きで完全解説します。
第1章|なぜseabornなのか|matplotlibとの違い
seabornは「matplotlibの進化版」
seabornは、matplotlibを基盤に作られた「より美しく、より統計的」なグラフライブラリです。
- デフォルトのデザインが洗練されている(プロ品質)
- 統計的なグラフ(ヒートマップ・分布図など)を1行で作れる
- pandasのDataFrameと相性が抜群
- matplotlibと併用できる(学習コストが低い)
matplotlib vs seaborn 比較
| 観点 | matplotlib | seaborn |
|---|---|---|
| デザイン | 素朴・カスタマイズ前提 | 最初から美しい |
| 統計グラフ | 自分で計算して描画 | 1行で描ける |
| DataFrame連携 | やや手間 | そのまま渡せる |
| カスタマイズ性 | ◎ 細部まで自由 | ○ 主要設定はOK |
| 学習難易度 | 中 | 低 |
使い分けの結論
両者は対立関係ではなく、補完関係です。
- **基本のグラフを素早く美しく描きたい** → seaborn
- **細部まで自由にカスタマイズしたい** → matplotlib
- **両方を組み合わせる** → 最強
実際、seabornで描いたグラフをmatplotlibの関数で微調整するのが、データサイエンス業務の定番パターンです。
第2章|環境準備(uv環境前提)
この記事は、uv環境でPythonを使う前提で進めます。まだuvをインストールしていない方は、別記事「【完全版】uv入門」をご覧ください。
必要なライブラリ
# seabornをインストール(matplotlibとpandasも自動でインストールされる)
uv add seaborn日本語フォント設定
matplotlib同様、日本語表示にはフォント設定が必要です。確実に動く方法を紹介します。
import matplotlib
# 日本語フォント設定(Windows)
matplotlib.rcParams["font.family"] = "Meiryo"
# Macの場合は以下に変更
# matplotlib.rcParams["font.family"] = "Hiragino Sans"第3章|seabornの基本|デザインが一発で整う
seabornの最大の魅力は、「**何もしなくても美しい**」こと。同じデータをmatplotlibとseabornで描いて比較してみます。
matplotlibで棒グラフ(参考)
import matplotlib.pyplot as plt
import matplotlib
# 日本語フォント設定
matplotlib.rcParams["font.family"] = "Meiryo"
# データを準備
products = ["商品A", "商品B", "商品C", "商品D"]
sales = [180, 120, 90, 150]
# matplotlibで棒グラフ
plt.bar(products, sales)
plt.title("商品別売上")
plt.show()シンプルな棒グラフが描けます。
seabornで棒グラフ
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
# 日本語フォント設定
matplotlib.rcParams["font.family"] = "Meiryo"
# データをDataFrameで準備
# seabornはDataFrameと相性が良い
df = pd.DataFrame({
"商品": ["商品A", "商品B", "商品C", "商品D"],
"売上": [180, 120, 90, 150]
})
# seabornで棒グラフ(barplot関数)
# x軸とy軸にカラム名を指定するだけ
sns.barplot(data=df, x="商品", y="売上")
plt.title("商品別売上")
plt.show()同じデータでも、seabornで描くと**自動的に美しい配色・グリッド**が適用されます。
seabornが用意する主要グラフ関数
| 関数 | 用途 |
|---|---|
| barplot | 棒グラフ(カテゴリ別の平均値などを表示) |
| lineplot | 折れ線グラフ(時系列推移など) |
| scatterplot | 散布図(2変数の関係を見る) |
| histplot | ヒストグラム(分布を見る) |
| boxplot | 箱ひげ図(ばらつきを見る) |
| heatmap | ヒートマップ(行列の値を色で表現) |
| pairplot | 複数変数の関係を一気に可視化 |
第4章|統計的なグラフを描く
seabornの真価は「統計的なグラフを1行で描ける」点。matplotlibでは手間がかかるグラフが、驚くほど簡単に作れます。
ヒストグラム(データの分布を見る)
「顧客の購入金額の分布」「テストの点数分布」など、データの広がりを可視化します。
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
matplotlib.rcParams["font.family"] = "Meiryo"
# サンプルデータ:100人の購入金額(平均5000円、ばらつき1500円)
# np.random.normal で正規分布のデータを生成
np.random.seed(42) # 結果を再現可能にする
amount = np.random.normal(5000, 1500, 100)
df = pd.DataFrame({"購入金額": amount})
# ヒストグラム
# bins=20 で棒の数を20本に
# kde=True で滑らかな曲線(密度推定)も表示
sns.histplot(data=df, x="購入金額", bins=20, kde=True)
plt.title("顧客の購入金額分布")
plt.show()箱ひげ図(カテゴリ別のばらつきを見る)
「店舗別の売上ばらつき」「商品カテゴリ別の利益率ばらつき」など、グループ間の比較に最適です。
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
matplotlib.rcParams["font.family"] = "Meiryo"
# サンプルデータ:3店舗×30日分の売上
np.random.seed(42)
data = []
for store in ["東京店", "大阪店", "名古屋店"]:
# 店舗ごとに異なる平均で30日分の売上を生成
base = {"東京店": 200, "大阪店": 180, "名古屋店": 160}[store]
for day in range(30):
data.append({
"店舗": store,
"売上": base + np.random.normal(0, 30)
})
df = pd.DataFrame(data)
# 箱ひげ図
sns.boxplot(data=df, x="店舗", y="売上")
plt.title("店舗別売上のばらつき")
plt.show()ヒートマップ(行列の値を色で表現)
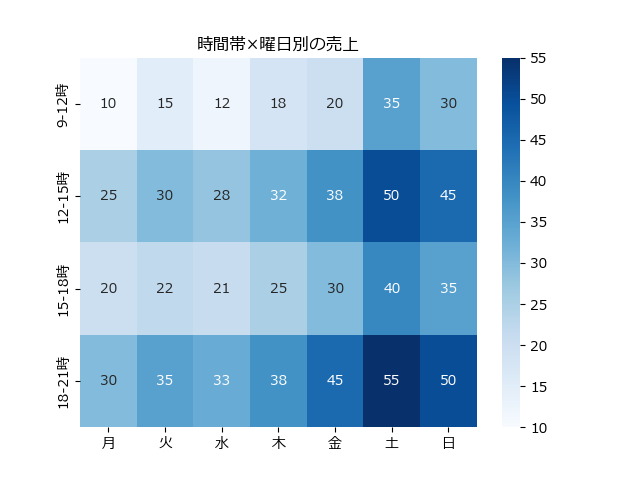
「時間帯×曜日の売上」「項目間の相関」など、2次元のデータを直感的に可視化します。
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
matplotlib.rcParams["font.family"] = "Meiryo"
# サンプルデータ:時間帯×曜日の売上
# pd.DataFrameで2次元データを作成
data = np.array([
[10, 15, 12, 18, 20, 35, 30], # 9-12時
[25, 30, 28, 32, 38, 50, 45], # 12-15時
[20, 22, 21, 25, 30, 40, 35], # 15-18時
[30, 35, 33, 38, 45, 55, 50], # 18-21時
])
df = pd.DataFrame(
data,
index=["9-12時", "12-15時", "15-18時", "18-21時"],
columns=["月", "火", "水", "木", "金", "土", "日"]
)
# ヒートマップ
# annot=True で各セルに数値を表示
# cmap="Blues" で青系のカラーマップ(マイペースブログカラー)
# fmt="d" で整数表示
sns.heatmap(df, annot=True, cmap="Blues", fmt="d")
plt.title("時間帯×曜日別の売上")
plt.show()
第5章|データ間の関係を可視化する
seabornは「複数の変数間の関係」を可視化するのも得意。データ分析業務で頻出のテクニックを紹介します。
散布図(2変数の関係を見る)
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
matplotlib.rcParams["font.family"] = "Meiryo"
# サンプルデータ:広告費と売上の関係(30件)
np.random.seed(42)
ad_cost = np.random.uniform(10, 100, 30)
# 広告費に正の相関がある売上を生成(ばらつきも追加)
sales = ad_cost * 5 + np.random.normal(0, 30, 30)
df = pd.DataFrame({
"広告費": ad_cost,
"売上": sales
})
# 散布図
sns.scatterplot(data=df, x="広告費", y="売上")
plt.title("広告費と売上の関係")
plt.show()回帰直線付き散布図(相関を可視化)
散布図に「回帰直線」を加えると、データの傾向が一目で分かります。これがseabornの真骨頂。
# 回帰直線付き散布図
# regplot は scatterplot + 回帰直線
sns.regplot(data=df, x="広告費", y="売上")
plt.title("広告費と売上の関係(回帰直線付き)")
plt.show()matplotlibだと、回帰計算を別途やってから線を引く必要がありますが、seabornなら1行で完結します。
相関ヒートマップ(複数変数の関係を一気に)
「売上」「広告費」「来店数」「気温」など、複数の指標間の相関を一目で確認できます。
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
matplotlib.rcParams["font.family"] = "Meiryo"
# サンプルデータ:複数の指標
np.random.seed(42)
n = 100
df = pd.DataFrame({
"売上": np.random.normal(100, 20, n),
"広告費": np.random.normal(50, 15, n),
"来店数": np.random.normal(80, 25, n),
"気温": np.random.normal(20, 5, n),
})
# 相関係数を計算
# corr() は各列の相関係数を行列で返す
corr_matrix = df.corr()
# 相関ヒートマップ
# annot=True で相関係数の数値を表示
# cmap="coolwarm" で正負を色で区別
# vmin/vmax で色の範囲を-1〜1に固定
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm", vmin=-1, vmax=1, fmt=".2f")
plt.title("指標間の相関係数")
plt.show()これは**データ分析業務で最初にやる定番の可視化**。データ間の関係を一気に把握できます。
第6章|カスタマイズ|色・テーマ・スタイル
テーマの変更(一括デザイン変更)
seabornには複数のデフォルトテーマが用意されています。
import seaborn as sns
# テーマを変更(5種類から選択)
sns.set_theme(style="whitegrid") # 白背景・グリッドあり(デフォルト推奨)
# sns.set_theme(style="darkgrid") # 暗背景・グリッド
# sns.set_theme(style="white") # 白背景・グリッドなし
# sns.set_theme(style="dark") # 暗背景・グリッドなし
# sns.set_theme(style="ticks") # 軸目盛り強調カラーパレットの変更
# カラーパレットを変更
sns.set_palette("Blues") # 青系(マイペースブログカラー)
# sns.set_palette("husl") # 鮮やかな色
# sns.set_palette("Set2") # 落ち着いた色
# sns.set_palette("pastel") # パステル調
# カスタムパレット(独自の色を指定)
custom_colors = ["#003d99", "#0066ff", "#4d94ff", "#80b3ff"]
sns.set_palette(custom_colors)マイペースブログ青系の統一設定
import seaborn as sns
import matplotlib
# 日本語フォント
matplotlib.rcParams["font.family"] = "Meiryo"
# マイペースブログのカラーパレット
mypace_blue = ["#003d99", "#0066ff", "#4d94ff", "#80b3ff", "#b3d1ff"]
# テーマとカラーをセット
sns.set_theme(style="whitegrid", palette=mypace_blue)
# これで以降のすべてのグラフが青系に統一される第7章|実務で使える完成スクリプト
実務で使えるよう、データ読み込みから美しいグラフ出力までを一括で行うスクリプトです。
売上データから複数グラフを一括生成
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
from datetime import datetime
# マイペースブログのカラーパレット
mypace_blue = ["#003d99", "#0066ff", "#4d94ff", "#80b3ff", "#b3d1ff"]
sns.set_theme(style="whitegrid", palette=mypace_blue)
# === 設定 ===
# 日本語フォント
matplotlib.rcParams["font.family"] = "Meiryo"
# === サンプルデータ生成 ===
# 実務では pd.read_excel() などで読み込む
np.random.seed(42)
n = 200 # 200件の売上データ
df = pd.DataFrame({
"日付": pd.date_range(start="2026-01-01", periods=n, freq="D"),
"店舗": np.random.choice(["東京店", "大阪店", "名古屋店"], n),
"商品": np.random.choice(["商品A", "商品B", "商品C", "商品D"], n),
"売上": np.random.normal(50000, 15000, n).astype(int),
})
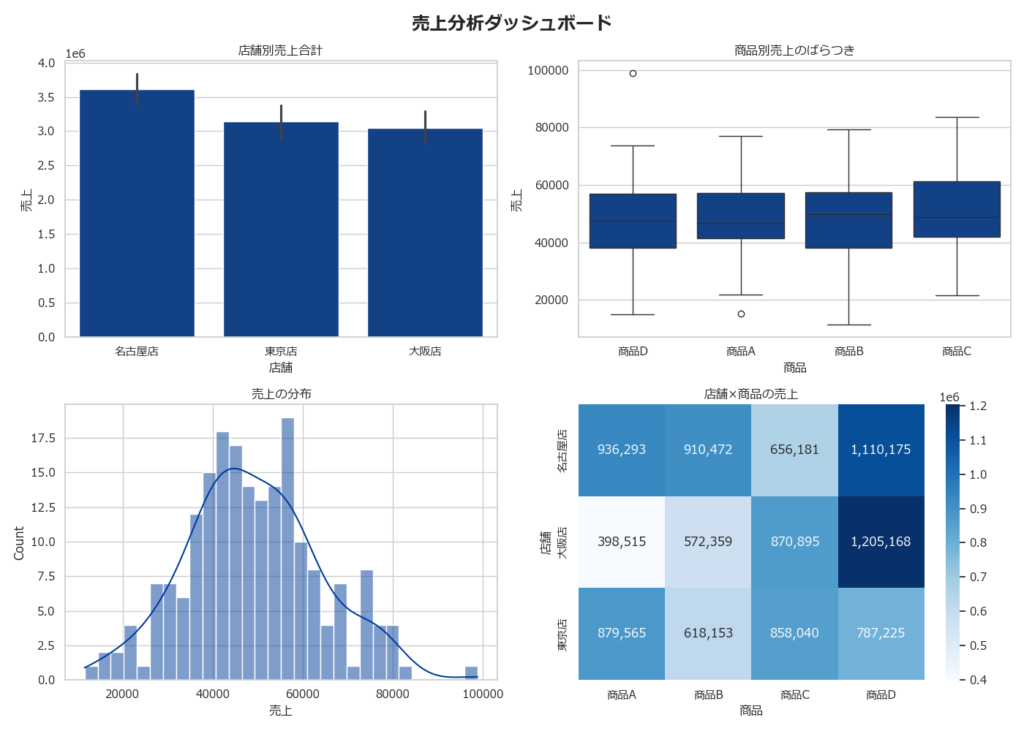
# === 4種類のグラフを一括生成 ===
# 2x2のサブプロットを作成
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# グラフ1:店舗別売上の合計(棒グラフ)
sns.barplot(
data=df, x="店舗", y="売上", estimator=sum, ax=axes[0, 0]
)
axes[0, 0].set_title("店舗別売上合計")
# グラフ2:商品別売上の分布(箱ひげ図)
sns.boxplot(data=df, x="商品", y="売上", ax=axes[0, 1])
axes[0, 1].set_title("商品別売上のばらつき")
# グラフ3:売上の分布(ヒストグラム)
sns.histplot(data=df, x="売上", bins=30, kde=True, ax=axes[1, 0])
axes[1, 0].set_title("売上の分布")
# グラフ4:店舗×商品のヒートマップ
# pivot_tableで2次元集計
pivot = df.pivot_table(
values="売上", index="店舗", columns="商品", aggfunc="sum"
)
sns.heatmap(
pivot, annot=True, fmt=",.0f", cmap="Blues", ax=axes[1, 1]
)
axes[1, 1].set_title("店舗×商品の売上")
# 全体のタイトル
fig.suptitle("売上分析ダッシュボード", fontsize=18, fontweight="bold")
plt.tight_layout()
# ファイルに保存
# dpi=300 で高解像度(印刷品質)
output_file = f"売上ダッシュボード_{datetime.now().strftime('%Y%m%d')}.png"
plt.savefig(output_file, dpi=300, bbox_inches="tight")
print(f"保存しました:{output_file}")
plt.show()このスクリプトでできること
- 4種類のグラフ(棒・箱ひげ・ヒストグラム・ヒートマップ)を一括生成
- マイペースブログの青系カラーで統一
- 実行日付付きの高解像度PNG画像として保存
- クライアントレポート・経営会議資料にそのまま使える品質
第8章|つまずき対処&まとめ
よくあるトラブル
トラブル1:日本語が文字化けする
対処:
import matplotlib
# Windowsの場合
matplotlib.rcParams["font.family"] = "Meiryo"
# Macの場合
# matplotlib.rcParams["font.family"] = "Hiragino Sans"トラブル2:seabornのテーマが効かない
対処:
# テーマ設定は「グラフを描く前」に呼ぶ
import seaborn as sns
sns.set_theme(style="whitegrid") # ←グラフ描画より前
# その後にグラフ描画
sns.barplot(...)トラブル3:ヒートマップに数値が表示されない
対処:
# annot=True を必ず指定
sns.heatmap(df, annot=True, fmt="d") # 整数表示
sns.heatmap(df, annot=True, fmt=".2f") # 小数2桁表示トラブル4:データが多すぎてグラフが重い
対処:
数万行以上のデータでは、scatterplotは描画が遅くなります。サンプリング(df.sample(1000)など)で間引くか、ヒートマップに置き換えるのが有効です。
この記事のまとめ
- seabornはmatplotlibを進化させた、美しい統計グラフライブラリ
- デフォルトデザインが美しく、プロ品質のグラフが一発で描ける
- ヒストグラム・箱ひげ図・ヒートマップなど、統計的なグラフが1行で作れる
- 回帰直線付き散布図、相関ヒートマップなど、データ分析業務に直結する機能が豊富
- matplotlibと併用できるため、学習コストが低く、応用範囲も広い
FAQ
美しい可視化が、伝わるレポートを作る
seabornを使えば、同じデータでも「数倍伝わるグラフ」が作れます。
マイペースブログでは、今後もデータ可視化・データ分析に関する記事を発信していきます。次は重回帰分析やSHAPなど、「データから物語を引き出す」テクニックも紹介予定です。
最新の解説記事は、新着記事から順次公開しています。X(旧Twitter)でも更新情報を発信していますので、ぜひフォローしてください。
この記事を書いた人
ソニック|バックオフィス出身の業務効率化ブロガー。データサイエンス業務でクライアント向けレポートの可視化にseabornを日常的に活用。リアルな実体験をもとにしたノウハウを発信中。
コメント