
 ソニック
ソニックペアプロット・回帰分析・カテゴリ分析で「データから物語を引き出す」
「データはあるけど、どう分析すればいいか分からない」「上司にデータ分析を頼まれたが、何から始めるべきか」
そんな悩み、データに触れ始めた方なら必ず通る道です。
前回の「seabornで統計グラフを作る」では、基本的な統計グラフの描き方を解説しました。今回はその応用編――**データから「物語」を引き出すための深い統計可視化**を扱います。
データ分析は「綺麗なグラフを描くこと」ではなく、「データに語らせること」。seabornの応用テクニックを身につければ、あなたもデータの物語を読める人になれます。
私自身、データサイエンス業務で日々seabornを使い、顧客の経営判断を支える分析レポートを作成しています。この記事では、現場で本当に使えるテクニックだけを厳選して紹介します。
こんな方におすすめ
- seabornの基本は分かったが、応用テクニックを学びたい方
- データから「気づき」を引き出す可視化を実現したい方
- 将来データ分析を仕事にしたい、副業に活かしたい方
第1章|なぜ「深い統計可視化」が必要か
「綺麗なグラフ」と「物語を語るグラフ」の違い
世の中には2種類のグラフがあります。
- **綺麗なグラフ**:数字を見やすく並べただけのグラフ
- **物語を語るグラフ**:データの構造・傾向・異常を「気づかせる」グラフ
ビジネスで価値があるのは、後者です。
Before/After|深い可視化の威力
| 分析ニーズ | Before(基本グラフ) | After(応用テクニック) |
|---|---|---|
| 変数間の関係 | 1つずつ散布図 | ペアプロットで一気に |
| 回帰の妥当性確認 | 回帰直線だけ表示 | 残差プロットで検証 |
| カテゴリ別の分布 | 箱ひげ図のみ | violin+swarmplot |
| 複数指標の比較 | グラフを並べる | FacetGridで自動配置 |
データ分析の世界への扉
深い統計可視化を身につけることは、データ分析の世界への扉を開くことでもあります。
- 「データを見る目」が養われる
- 社内で「数字に強い人」と認識される
- データ分析業務への転職・副業への道が開く
※当ブログでは、今後「データ分析」カテゴリの新設も検討中。重回帰分析・SHAP・LightGBM等の解説も準備しています。
第2章|環境準備+前回記事の復習
この記事は、前回の「seabornで統計グラフを作る完全ガイド」の続編です。基本がまだの方は、先に前回記事をご覧ください。
環境準備
# seabornと関連ライブラリをインストール
uv add seaborn pandas numpy共通設定(毎回コピペでOK)
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
# 日本語フォント設定(Windows)
matplotlib.rcParams["font.family"] = "Meiryo"
# Macの場合
# matplotlib.rcParams["font.family"] = "Hiragino Sans"
# マイペースブログのカラーパレット
mypace_blue = ["#003d99", "#0066ff", "#4d94ff", "#80b3ff", "#b3d1ff"]
sns.set_theme(style="whitegrid", palette=mypace_blue)以下、各章のコードはこの共通設定を済ませた前提で進めます。
第3章|ペアプロット|全変数を一気に可視化
ペアプロットとは
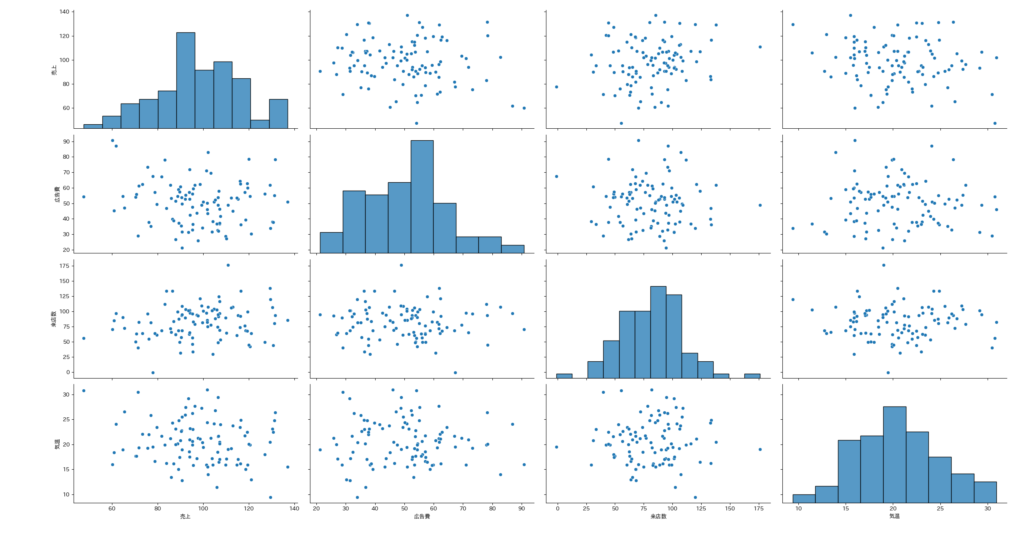
**pairplot関数**を使うと、複数の変数の関係を**一気にマトリクス表示**できます。データ分析の初期探索(EDA:探索的データ分析)で頻出のテクニックです。
基本のペアプロット
uv add setuptoolsimport matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
import japanize_matplotlib
# サンプルデータ:店舗の指標
np.random.seed(42)
n = 100
df = pd.DataFrame({
"売上": np.random.normal(100, 20, n),
"広告費": np.random.normal(50, 15, n),
"来店数": np.random.normal(80, 25, n),
"気温": np.random.normal(20, 5, n),
})
# ペアプロット:全変数の組み合わせを散布図でマトリクス表示
# 対角線上はヒストグラム、それ以外は散布図
sns.pairplot(df)
plt.show()**1行のコード**で、4×4=16個のグラフが一気に生成されます。データの全体像が一目で把握できる、データ分析業務の最強テクニックです。
カテゴリ別に色分けしたペアプロット
カテゴリ列を追加して、グループごとに色分けすると更に深い分析になります。
# 店舗カテゴリを追加
df["店舗"] = np.random.choice(["東京", "大阪", "名古屋"], n)
# hue引数で色分け
# diag_kind="kde" で対角線を密度推定に
sns.pairplot(df, hue="店舗", diag_kind="kde")
plt.show()実務での使い方
- **初めて見るデータの探索**:データの全体構造を一気に把握
- **外れ値の発見**:散布図群から異常値を視覚的に検出
- **特徴量選択**:機械学習で使う変数を選ぶ判断材料
- **プレゼン資料の起点**:ここから個別の深掘りグラフを作る
第4章|回帰分析の可視化|lmplot・residplot
lmplot|複数のサブグループで回帰直線を比較
**lmplot**は、回帰直線をカテゴリ別に同時に描けます。「店舗別の広告費効果の違い」などを一発で可視化。
# サンプルデータ:3店舗の広告費と売上
np.random.seed(42)
data = []
for store in ["東京店", "大阪店", "名古屋店"]:
# 店舗ごとに広告効果が異なる設定
slope = {"東京店": 5, "大阪店": 4, "名古屋店": 3}[store]
for _ in range(30):
ad = np.random.uniform(10, 100)
sales = ad * slope + np.random.normal(0, 30)
data.append({"店舗": store, "広告費": ad, "売上": sales})
df = pd.DataFrame(data)
# lmplot:カテゴリ別に回帰直線を描く
# col引数で「列ごとに別グラフ」も可能
sns.lmplot(data=df, x="広告費", y="売上", hue="店舗", height=5)
plt.show()店舗ごとの広告効果の違い(傾き)が一目で分かります。**経営判断に直結する分析**です。
residplot|残差プロットで回帰の妥当性を確認
**residplot**は、回帰モデルの「残差(予測のズレ)」を可視化します。データ分析業務で必須のチェックです。
# 残差プロット
# 残差にパターンがあれば、線形回帰では不十分のサイン
sns.residplot(data=df, x="広告費", y="売上")
plt.title("残差プロット(広告費 vs 売上)")
plt.show()残差プロットの読み方
- **点がランダムに散らばっている** → 線形回帰でOK
- **曲線パターンが見える** → 非線形モデル(多項式回帰など)を検討
- **ばらつきが偏っている** → 異分散の問題(変数変換が必要)
※残差プロットは、データ分析の現場で「モデルが正しいか」を見るための定番チェック。プロのデータアナリストは必ず確認します。
第5章|カテゴリ分析|violinplot・swarmplot
violinplot|分布の形まで見える
**箱ひげ図の進化版**。データの「分布の形状」まで可視化できます。
# サンプルデータ:3店舗×50日分の売上
np.random.seed(42)
data = []
for store in ["東京店", "大阪店", "名古屋店"]:
base = {"東京店": 100, "大阪店": 90, "名古屋店": 80}[store]
for _ in range(50):
data.append({
"店舗": store,
"売上": base + np.random.normal(0, 20)
})
df = pd.DataFrame(data)
# violinplot:分布の形まで表示
sns.violinplot(data=df, x="店舗", y="売上")
plt.title("店舗別売上の分布形状")
plt.show()箱ひげ図では分からない**分布の偏り(左右非対称・複数ピーク)**まで一目で見えます。
swarmplot|個々のデータ点を全て表示
**swarmplot**は、データ点を重ならないように配置します。「実際のデータ点」を全て見せたい時に最適。
# swarmplot:データ点を全て表示
sns.swarmplot(data=df, x="店舗", y="売上", size=4)
plt.title("店舗別売上(個別データ点)")
plt.show()violinplot+swarmplotの組み合わせ(最強)
両者を重ねると、「分布の傾向+個別データ」の両方が一目で見える究極の可視化に。
# 2つを重ねる
fig, ax = plt.subplots(figsize=(10, 6))
# 透明度を下げてviolin
sns.violinplot(data=df, x="店舗", y="売上", inner=None, alpha=0.5, ax=ax)
# データ点を重ねる
sns.swarmplot(data=df, x="店舗", y="売上", size=3, color="black", ax=ax)
plt.title("店舗別売上|分布+個別データ")
plt.show()第6章|時系列データの可視化|lineplot応用
信頼区間付きlineplot
**lineplot**は、複数のサンプルがあれば自動で信頼区間(薄い帯)を描画します。これがseabornの強みです。
# サンプルデータ:12ヶ月×3店舗×複数日の売上
np.random.seed(42)
data = []
for month in range(1, 13):
for store in ["東京店", "大阪店", "名古屋店"]:
# 各月に複数のデータポイントを生成
for _ in range(10):
base = {"東京店": 100, "大阪店": 90, "名古屋店": 80}[store]
seasonal = 20 * np.sin(month * np.pi / 6) # 季節性
data.append({
"月": month,
"店舗": store,
"売上": base + seasonal + np.random.normal(0, 10)
})
df = pd.DataFrame(data)
# lineplot:自動で信頼区間が描画される
sns.lineplot(data=df, x="月", y="売上", hue="店舗", marker="o")
plt.title("月別売上推移(信頼区間付き)")
plt.show()**薄い帯**が信頼区間です。「この帯が狭い=予測の確実性が高い」と読み取れます。
FacetGrid|カテゴリ別に複数グラフを自動生成
**FacetGrid**は、カテゴリ別にグラフを自動でレイアウトしてくれます。
# 店舗ごとに別グラフ
g = sns.FacetGrid(df, col="店舗", height=4, aspect=1.2)
g.map_dataframe(sns.lineplot, x="月", y="売上", marker="o")
g.set_titles("{col_name}")
g.fig.suptitle("店舗別売上推移", y=1.05)
plt.show()**サブプロットを自分で組まなくても**、カテゴリ別に綺麗に並んだグラフが完成します。
第7章|実務スクリプト|売上データの統計探索
シナリオ
「3店舗の売上データを受け取った。これから経営層に分析報告したい」――そんな時の**統計探索一括スクリプト**です。
完成スクリプト
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
import numpy as np
from datetime import datetime
# === 共通設定 ===
matplotlib.rcParams["font.family"] = "Meiryo"
mypace_blue = ["#003d99", "#0066ff", "#4d94ff", "#80b3ff", "#b3d1ff"]
sns.set_theme(style="whitegrid", palette=mypace_blue)
# === サンプルデータ生成 ===
# 実務では pd.read_excel() などで読み込む
np.random.seed(42)
n = 300
df = pd.DataFrame({
"日付": pd.date_range(start="2026-01-01", periods=n, freq="D"),
"店舗": np.random.choice(["東京店", "大阪店", "名古屋店"], n),
"商品": np.random.choice(["商品A", "商品B", "商品C"], n),
"広告費": np.random.uniform(10, 100, n),
"売上": np.random.normal(50000, 15000, n).astype(int),
"来店数": np.random.normal(80, 20, n).astype(int),
})
# === ステップ1:全変数の関係を可視化 ===
# ペアプロットで全体像を把握
print("ステップ1:ペアプロット作成中...")
sns.pairplot(df[["広告費", "売上", "来店数"]], height=2.5)
plt.suptitle("変数間の関係性(ペアプロット)", y=1.02)
plt.savefig(f"01_ペアプロット_{datetime.now().strftime('%Y%m%d')}.png", dpi=150, bbox_inches="tight")
plt.show()
# === ステップ2:店舗別の広告費効果を回帰分析 ===
print("ステップ2:店舗別回帰分析中...")
sns.lmplot(data=df, x="広告費", y="売上", hue="店舗", height=5)
plt.title("店舗別|広告費の売上への効果")
plt.savefig(f"02_店舗別回帰_{datetime.now().strftime('%Y%m%d')}.png", dpi=150, bbox_inches="tight")
plt.show()
# === ステップ3:店舗別売上の分布を比較 ===
print("ステップ3:分布比較中...")
fig, ax = plt.subplots(figsize=(10, 6))
sns.violinplot(data=df, x="店舗", y="売上", inner=None, alpha=0.5, ax=ax)
sns.swarmplot(data=df, x="店舗", y="売上", size=2, color="black", ax=ax)
plt.title("店舗別売上分布")
plt.savefig(f"03_店舗別分布_{datetime.now().strftime('%Y%m%d')}.png", dpi=150, bbox_inches="tight")
plt.show()
# === ステップ4:相関ヒートマップ ===
print("ステップ4:相関分析中...")
corr = df[["広告費", "売上", "来店数"]].corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, cmap="coolwarm", vmin=-1, vmax=1, fmt=".2f")
plt.title("指標間の相関係数")
plt.savefig(f"04_相関ヒートマップ_{datetime.now().strftime('%Y%m%d')}.png", dpi=150, bbox_inches="tight")
plt.show()
print("\n完了:4種類の分析グラフを保存しました")このスクリプトでできること
- **ステップ1**:データ全体像をペアプロットで把握
- **ステップ2**:店舗別の回帰分析で「どの店舗が広告効果が高いか」を可視化
- **ステップ3**:分布の比較で「ばらつきの違い」を発見
- **ステップ4**:相関ヒートマップで「どの指標が連動しているか」を確認
**4枚の画像が高解像度で保存**され、そのまま経営報告に使える品質のレポート素材になります。
第8章|つまずき対処&まとめ+次のステップ
よくあるトラブル
トラブル1:ペアプロットが重い
対処:
変数が多すぎる、またはデータ量が多すぎる可能性があります。
# 変数を絞る
sns.pairplot(df[["売上", "広告費", "来店数"]])
# データをサンプリング
sns.pairplot(df.sample(500))トラブル2:lmplotとregplotの違いは?
解説:
- **regplot**:1つのグラフに1本の回帰直線
- **lmplot**:カテゴリ別に色分け・分割表示が可能(FacetGrid内蔵)
トラブル3:violinplotの軸が見づらい
対処:
# y軸の範囲を調整
ax = sns.violinplot(data=df, x="店舗", y="売上")
ax.set_ylim(0, df["売上"].max() * 1.1)この記事のまとめ
- ペアプロットは「データ全体像把握」の最強テクニック
- lmplot+residplotで回帰分析の妥当性まで確認
- violinplot+swarmplotで分布と個別データを同時に可視化
- FacetGridでカテゴリ別グラフを自動生成
- 実務では「ペアプロット→深掘り」の流れが定石
FAQ
次にやるべき3つの行動
- **今すぐ**:自分の手元にある業務データに対して、ペアプロットを実行してみる
- **今日中**:相関ヒートマップで「意外な関係性」を1つ発見する
- **今週中**:実務スクリプトを応用して、上司や同僚に1枚の分析レポートを提出してみる
データを「見る」から「読む」へ。この一歩が、あなたのキャリアを大きく変えます。
データ分析の世界、次のステップへ
seabornの応用テクニックを身につけたあなたは、もう「ただのExcel使い」ではありません。**データから物語を引き出せる人**です。
当ブログでは、今後**データ分析カテゴリ**の新設を計画しています。具体的には:
- 重回帰分析|複数要因の影響を定量化する
- SHAP|AI予測の「なぜ」を説明可能にする
- LightGBM|実務で使える機械学習モデル
- クラスタリング|顧客セグメント分析
X(旧Twitter)でも更新情報を発信していますので、最新記事を見逃さないようぜひフォローしてください。
この記事を書いた人
ソニック|バックオフィス出身の業務効率化ブロガー。データサイエンス業務でクライアント向けの分析レポート作成にseabornを毎日活用。「データに物語らせる」可視化を信条に、リアルな実体験をもとにしたノウハウを発信中。
コメント