
 ソニック
ソニックデータを地図で可視化する|plotly mapの完全実用テクニック
「店舗別の売上データを、地図で可視化したい」「顧客の住所分布をビジュアルで把握したい」「災害時の影響エリアを瞬時に確認したい」
そんなニーズに完璧に応えるのが、Pythonの「plotly」ライブラリです。
私自身、データサイエンス業務で顧客の店舗分析・配送エリア最適化レポートを作成する際、plotlyの地図機能をフル活用しています。Excelの表だけでは絶対に見えない「地理的な物語」が、地図にプロットするだけで一瞬で見えるようになります。
地図ダッシュボードは、データ分析の「最強の表現方法」。住所データという当たり前の情報が、ビジネスを動かす武器に変わります。
この記事では、plotlyで地図ダッシュボードを作る方法を、コピペで動くコード付きで完全解説します。
こんな方におすすめ
- 店舗別・地域別の分析を地図で可視化したいビジネス担当者の方
- 顧客分布や配送エリアを最適化したい営業・物流の方
- Pythonでの本格的なダッシュボード作成に挑戦したい方
第1章|なぜ「地図ダッシュボード」が業務を変えるのか
「住所のデータ」は宝の山
ほとんどの企業が顧客・店舗・物件などの住所データを持っています。しかし、その多くが「Excelの表に並んだ文字列」として眠ったまま。
住所データは地図に落とした瞬間、別の情報になります。「分布」「集中」「外れ」――地理的な物語が浮かび上がります。
地図可視化が活躍する5つのシーン
- **店舗網と商圏分析**:店舗のカバー範囲、空白エリアの発見
- **顧客分布の可視化**:顧客の集中エリア、開拓余地の判断
- **配送ルート最適化**:物流コストを下げる最適なルート
- **災害リスク管理**:影響エリアの即座な把握
- **マーケティング戦略**:エリア別の広告投資判断
Before/After|地図ダッシュボードの威力
| 業務 | Before(表のみ) | After(地図可視化) |
|---|---|---|
| 店舗分布の把握 | 数値を見て想像 | 一目で把握 |
| 空白エリアの発見 | ほぼ不可能 | 地図上に可視化 |
| 経営層への説明 | 数字の羅列 | 地図で直感的に |
| 施策決定の速度 | 時間がかかる | 素早く判断 |
plotlyを選ぶ理由
- **インタラクティブ**:ズーム・パン・クリックで詳細表示
- **美しいデザイン**:そのままレポートに使える品質
- **HTML出力**:誰でもブラウザで閲覧可能
- **Mapboxとの連携**:プロ品質の地図タイル
- **Pythonとの相性**:pandas DataFrameをそのまま渡せる
第2章|環境準備(uv環境前提)
この記事は、uv環境でPythonを使う前提で進めます。まだuvをインストールしていない方は、別記事「【完全版】uv入門」をご覧ください。
必要なライブラリ
# plotlyとデータ処理用のライブラリ
uv add plotly pandas各ライブラリの役割
| ライブラリ | 役割 |
|---|---|
| plotly | インタラクティブな地図・グラフ描画 |
| pandas | 住所・座標データの読み込み・加工 |
地図のタイプの選択肢
plotlyには複数の地図モードがあります。本記事では一般的な「open-street-map」を使います。
- **open-street-map**:無料、APIキー不要、すぐ使える(推奨)
- **mapbox**:高品質、APIキーが必要、商用利用に最適
- **carto-positron**:シンプル、白基調
- **stamen-terrain**:地形重視
※本記事では「open-street-map」を使うため、APIキー登録や認証は不要です。すぐに地図ダッシュボードが作れます。
第3章|基本|plotlyで初めての地図を描く
最小の地図描画コード
まずは「地図上に1つの点を置く」だけのシンプルなコードから。
import plotly.express as px
import pandas as pd
# === サンプルデータ作成 ===
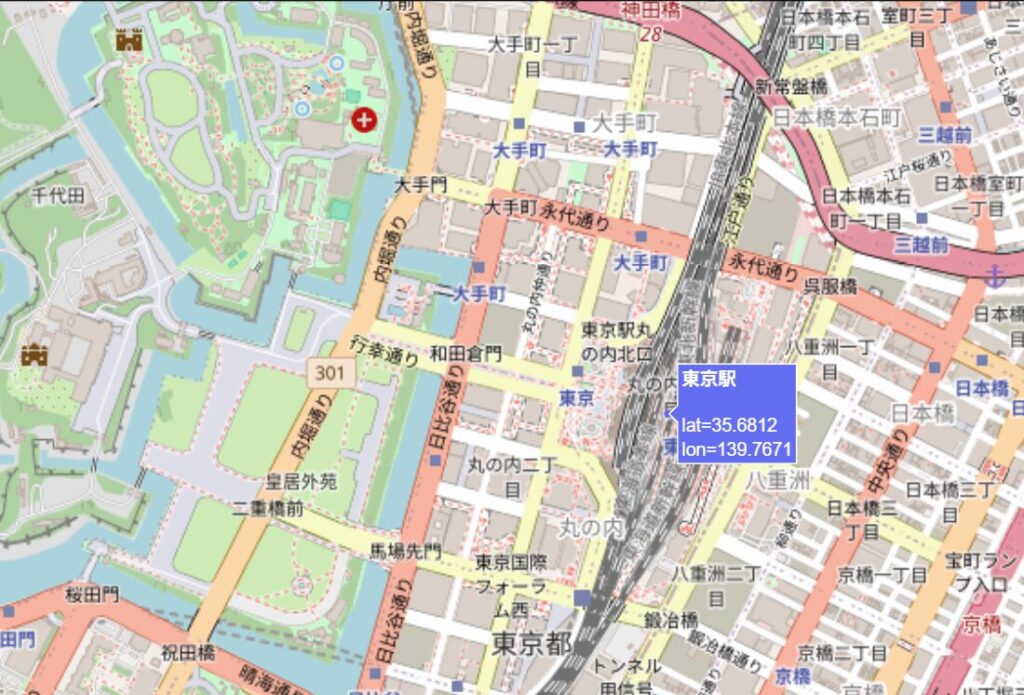
# 東京駅の緯度経度
df = pd.DataFrame({
"location": ["東京駅"],
"lat": [35.6812], # 緯度
"lon": [139.7671] # 経度
})
# === plotlyで地図を作成 ===
fig = px.scatter_map(
df, # データフレーム
lat="lat", # 緯度の列名
lon="lon", # 経度の列名
hover_name="location", # マウスホバー時に表示する列
zoom=10, # 初期ズームレベル(数値が大きいほど詳細)
height=500, # 高さ(ピクセル)
map_style="open-street-map" # 地図のスタイル
)
# 余白を調整
fig.update_layout(margin={"r": 0, "t": 0, "l": 0, "b": 0})
# 表示
fig.show()
# HTMLファイルとして保存
fig.write_html("地図_テスト.html")
print("地図を保存しました:地図_テスト.html")コードの解説
- **px.scatter_map**:散布図地図を作る関数(旧名scatter_mapbox)
- **lat/lon**:緯度経度の列を指定。Excelの住所からは事前に変換が必要
- **zoom**:1(世界全体)〜20(建物レベル)の範囲で指定
- **map_style**:背景の地図タイル。open-street-mapが無料で扱いやすい
- **write_html**:誰でもブラウザで開けるHTMLファイルとして保存可能
第4章|散布図地図|Scatter Mapboxで複数地点をプロット
複数地点を一度にプロット
実務では「複数の店舗」「複数の顧客」を地図に並べる場面が多いはずです。
import plotly.express as px
import pandas as pd
# === サンプルデータ:5店舗の情報 ===
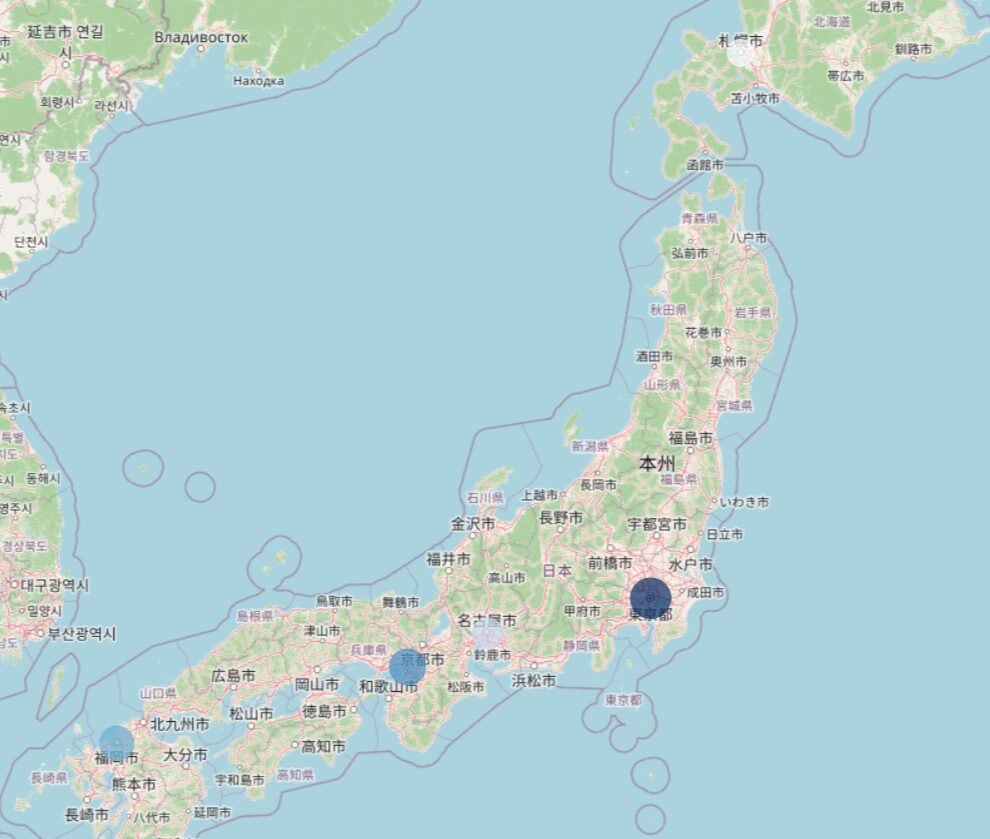
df = pd.DataFrame({
"店舗名": ["東京店", "大阪店", "名古屋店", "札幌店", "福岡店"],
"lat": [35.6812, 34.6937, 35.1815, 43.0642, 33.5904],
"lon": [139.7671, 135.5023, 136.9066, 141.3469, 130.4017],
"売上": [1500, 1200, 900, 700, 1100], # 売上(万円)
"従業員数": [20, 18, 12, 10, 15]
})
# === 地図を作成 ===
fig = px.scatter_map(
df,
lat="lat",
lon="lon",
hover_name="店舗名", # ホバー時のタイトル
hover_data=["売上", "従業員数"], # ホバー時の詳細情報
size="売上", # 売上に応じて点の大きさを変える
color="売上", # 売上に応じて色を変える
color_continuous_scale="Blues", # 青系のグラデーション
zoom=4, # 日本全体が見えるズーム
height=600,
map_style="open-street-map",
title="全国5店舗の売上分布"
)
fig.update_layout(margin={"r": 0, "t": 30, "l": 0, "b": 0})
fig.show()
fig.write_html("店舗売上_散布図地図.html")この地図が示すこと
- **点の大きさ** = 売上の大きさ(大きいほど高売上)
- **点の色** = 売上の大きさ(青が濃いほど高売上)
- **ホバー** = 店舗名・売上・従業員数の詳細表示
- **ズーム・パン** = ユーザーが自由に拡大縮小可能
第5章|ヒートマップ地図|密度を可視化する
Density Mapboxの使い方
「顧客が密集しているエリア」「事故が多発しているエリア」など、**密度の高い場所**を視覚化したい場合に使います。
import plotly.express as px
import pandas as pd
import numpy as np
# === サンプルデータ:東京周辺の300人の顧客住所 ===
# np.random.seed で結果を再現可能にする
np.random.seed(42)
n = 300
# 東京駅を中心にランダムに分布
df = pd.DataFrame({
"顧客ID": [f"C{i:03d}" for i in range(n)],
"lat": np.random.normal(35.68, 0.05, n), # 東京駅周辺
"lon": np.random.normal(139.77, 0.06, n)
})
# === ヒートマップ地図を作成 ===
fig = px.density_map(
df,
lat="lat",
lon="lon",
radius=10, # ヒートマップの強度
zoom=10,
height=600,
map_style="open-street-map",
title="顧客分布のヒートマップ",
color_continuous_scale="Blues"
)
fig.update_layout(margin={"r": 0, "t": 30, "l": 0, "b": 0})
fig.show()
fig.write_html("顧客分布_ヒートマップ.html")使い分けのポイント
- **点が10〜50個程度** → 散布図地図(個別データが見える)
- **点が100個以上** → ヒートマップ(密度で見せる)
- **「どこに集中しているか」を伝えたい** → ヒートマップが最適
第6章|コロプレス図|地域別の色塗り分け
コロプレス図(Choropleth)とは
**都道府県別の人口**、**市区町村別の売上**、**国別のGDP**――こうした地域別データを「**色の濃淡**」で表現するのがコロプレス図です。
簡易版:座標ベースのコロプレス代用
本格的なコロプレス図には「GeoJSON」と呼ばれる地理情報ファイルが必要です。ここでは、より簡単に作れる「scatter_map」を使った代用表現を紹介します。
import plotly.express as px
import pandas as pd
# === サンプルデータ:都道府県別の架空の売上 ===
df = pd.DataFrame({
"都道府県": ["北海道", "宮城", "東京", "愛知", "大阪", "広島", "福岡", "沖縄"],
"lat": [43.06, 38.27, 35.69, 35.18, 34.69, 34.40, 33.61, 26.21],
"lon": [141.35, 140.87, 139.69, 136.91, 135.50, 132.46, 130.42, 127.68],
"売上": [850, 600, 2100, 1500, 1800, 700, 900, 350]
})
fig = px.scatter_map(
df,
lat="lat",
lon="lon",
hover_name="都道府県",
hover_data={"売上": True, "lat": False, "lon": False},
size="売上",
size_max=60, # 最大点サイズを大きくしてエリア表現に
color="売上",
color_continuous_scale="Blues",
zoom=4,
height=600,
map_style="open-street-map",
title="都道府県別の売上規模"
)
fig.update_layout(margin={"r": 0, "t": 30, "l": 0, "b": 0})
fig.show()
fig.write_html("都道府県別売上.html")※完全なコロプレス図(県の形そのものを塗る)には px.choropleth_map + GeoJSON が必要です。地理院などからダウンロードできますが、初級者は上記の「大きな点で代用」する方法で十分実用的です。
第7章|実務スクリプト|店舗の売上を地図で可視化
ここまでの内容を統合した、実務で使える完成スクリプトです。CSVから店舗データを読み込み、複数の地図を一度に生成します。
CSVファイルの例(店舗データ.csv)
店舗名,lat,lon,売上,従業員数,オープン年
東京本店,35.6812,139.7671,2500,30,2015
新宿店,35.6896,139.7006,1800,22,2018
渋谷店,35.6580,139.7016,1500,18,2019
池袋店,35.7295,139.7109,1200,15,2020
品川店,35.6284,139.7387,900,12,2021完成スクリプト
"""
店舗売上地図ダッシュボード
- CSVから店舗データを読み込む
- 散布図地図とヒートマップを生成
- HTMLとして保存
"""
import plotly.express as px
import plotly.graph_objects as go
import pandas as pd
from datetime import datetime
# === 設定 ===
CSV_PATH = "店舗データ.csv"
OUTPUT_PREFIX = f"店舗地図_{datetime.now().strftime('%Y%m%d')}"
# === データ読み込み ===
df = pd.read_csv(CSV_PATH)
print(f"店舗データ読み込み完了:{len(df)}店舗")
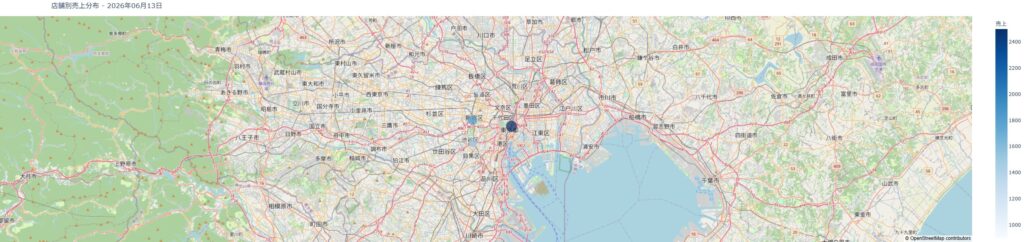
# === ① 散布図地図 ===
fig1 = px.scatter_map(
df,
lat="lat",
lon="lon",
hover_name="店舗名",
hover_data={
"売上": True,
"従業員数": True,
"オープン年": True,
"lat": False,
"lon": False
},
size="売上",
color="売上",
color_continuous_scale="Blues",
zoom=10,
height=600,
map_style="open-street-map",
title=f"店舗別売上分布 - {datetime.now().strftime('%Y年%m月%d日')}"
)
fig1.update_layout(margin={"r": 0, "t": 40, "l": 0, "b": 0})
fig1.write_html(f"{OUTPUT_PREFIX}_散布図.html")
print(f"散布図地図を保存:{OUTPUT_PREFIX}_散布図.html")
# === ② 売上ランキング(参考用の棒グラフ) ===
df_sorted = df.sort_values("売上", ascending=True)
fig2 = px.bar(
df_sorted,
x="売上",
y="店舗名",
orientation="h",
color="売上",
color_continuous_scale="Blues",
title="店舗別売上ランキング"
)
fig2.update_layout(height=400)
fig2.write_html(f"{OUTPUT_PREFIX}_ランキング.html")
print(f"ランキング表を保存:{OUTPUT_PREFIX}_ランキング.html")
# === ③ 統計サマリ ===
print("\n=== 統計サマリ ===")
print(f"総店舗数:{len(df)}店舗")
print(f"合計売上:{df['売上'].sum():,}万円")
print(f"平均売上:{df['売上'].mean():.0f}万円")
print(f"最高売上:{df.loc[df['売上'].idxmax(), '店舗名']}({df['売上'].max()}万円)")
print(f"最低売上:{df.loc[df['売上'].idxmin(), '店舗名']}({df['売上'].min()}万円)")このスクリプトでできること
- CSVから店舗データを読み込み
- 店舗別売上を地図で可視化(売上に応じてサイズ・色変化)
- 店舗ランキング棒グラフも自動生成
- HTMLファイルとして保存(誰でもブラウザで閲覧可能)
- 統計サマリ(合計・平均・最高・最低)も自動算出

第8章|つまずき対処&まとめ
よくあるトラブル
トラブル1:住所しかなく、緯度経度がない
対処:
住所→緯度経度の変換(ジオコーディング)が必要です。
# Geopyを使った住所→緯度経度変換
# uv add geopy
from geopy.geocoders import Nominatim
import time
geolocator = Nominatim(user_agent="my_app")
# 1件ずつ変換
address = "東京都千代田区丸の内1-9-1"
location = geolocator.geocode(address)
if location:
print(f"緯度:{location.latitude}, 経度:{location.longitude}")
# 大量データの場合は1秒間隔を空ける
time.sleep(1)トラブル2:地図が表示されない
原因:
plotlyのバージョンが古い、またはJupyterの設定問題。
対処:
# plotlyを最新版にアップデート
uv add --upgrade plotlyトラブル3:日本語が文字化けする
対処:
plotlyは内部的にUTF-8を使うため、CSVを正しいエンコードで読み込みます。
# UTF-8で読み込み
df = pd.read_csv("店舗.csv", encoding="utf-8")
# Shift_JISの場合
df = pd.read_csv("店舗.csv", encoding="shift_jis")トラブル4:データ点が密集して見えない
対処:
点の透明度を上げる、または別の可視化手法(ヒートマップ)に切り替えます。
# 点の透明度を調整(0=完全透明、1=不透明)
fig.update_traces(marker=dict(opacity=0.6))この記事のまとめ
- 住所データは「地図」にすることで、新しい価値を生む
- plotlyならインタラクティブな地図ダッシュボードが数十行で作れる
- 点が少ない→散布図地図、多い→ヒートマップ
- 緯度経度がない場合はGeopyでジオコーディング
- HTMLとして保存すれば、誰でもブラウザで閲覧可能
FAQ
次にやるべき3つの行動
- **今すぐ**:自社・自校の業務で「住所データ」をどう活用しているかリストアップ
- **今日中**:第3章の最小コードを実行し、地図に1点プロットしてみる
- **今週中**:自社の実データで散布図地図を作り、上司・同僚に見せる
Excelの住所データを「眠らせている」から「活かす」へ。地図ダッシュボードで、データの新しい使い方を始めましょう。
地図ダッシュボードで、業務の見え方が変わる
店舗網の最適化、顧客分布の把握、災害リスク管理――地理情報がビジネスを動かす場面は無限にあります。
plotlyの地図機能は、初心者でも数十行のコードでプロ品質のダッシュボードを作れる強力なツール。今日から、データの可能性を広げてください。
当ブログでは、データ分析・可視化に関する記事を順次公開しています。X(旧Twitter)でも更新情報を発信していますので、ぜひフォローしてください。
この記事を書いた人
ソニック|バックオフィス出身の業務効率化ブロガー。学校事務員時代に生徒の住所データを地図化した経験を活かし、現在のデータサイエンス業務では顧客分析・店舗分析の地図ダッシュボード制作にplotlyを毎日活用中。リアルな実体験をもとにしたノウハウを発信中。
コメント