

 ソニック
ソニック100ファイルが1分で完了
「フォルダに溜まった100個のExcelファイルを1つにまとめたい」
そんな業務、ありませんか?手作業では1日かかる作業が、Pythonならわずか1分で完了します。
この記事では、複数のExcelファイルを1つに統合するPythonコードを、コピペで使える形で完全解説します。基本のファイル統合から、ファイル名追加・複数シート統合まで、業務でそのまま使えるテクニックを網羅しました。
第1章|なぜ複数ファイル統合が必要か
こんな業務、ありませんか?
- 店舗別・部門別に分かれたExcelファイルを1つにまとめたい
- 月別に作成されたファイルを年間データとして統合したい
- 複数の担当者から提出されたファイルを集約したい
- バックアップとして残された日次ファイルを統合したい
私自身、学校事務員時代に、新入生のデータを担当者別に集めたファイルを統合する作業がありました。50個のファイルを開いてはコピペ、開いてはコピペ……。1日仕事でした。
これが、Pythonなら数行のコードで完了します。
Pythonで統合するメリット
| 観点 | 手作業 | Python |
|---|---|---|
| 100ファイル統合 | 1日仕事 | 約1分 |
| ヒューマンエラー | コピペミス頻発 | ゼロ |
| 再現性 | 毎回手動 | 実行ボタン1つ |
| ファイル数増加への対応 | 作業時間も比例 | 増えても数秒の差 |
第2章|環境準備(uv環境前提)
この記事は、uv環境でPythonを使う前提で進めます。まだuvをインストールしていない方は、以下の記事を先にご覧ください。

必要なライブラリの追加
uv add pandas openpyxlpandasはデータ処理、openpyxlはExcelファイルの読み書きに使います。
第3章|サンプルファイルの準備
実際にコードを動かすために、3つのサンプルExcelファイルを用意します。
フォルダ構成
my-project/
├── main.py
└── data/
├── 店舗A_売上.xlsx
├── 店舗B_売上.xlsx
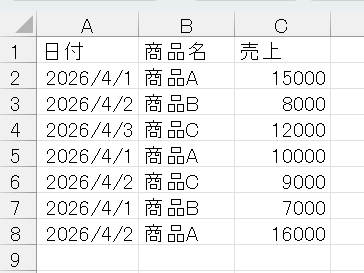
└── 店舗C_売上.xlsx各ファイルの中身(例)
3つのファイルすべて、同じ列構成(日付、商品名、売上)で作成してください。
店舗A_売上.xlsx:
日付,商品名,売上 2026-04-01,商品A,15000 2026-04-02,商品B,8000 2026-04-03,商品C,12000店舗B_売上.xlsx:
日付,商品名,売上 2026-04-01,商品A,10000 2026-04-02,商品C,9000店舗C_売上.xlsx:
日付,商品名,売上 2026-04-01,商品B,7000 2026-04-02,商品A,16000
第4章|基本|フォルダ内の全Excelを統合する
いよいよ統合のコードです。覚えるのは「glob」と「pd.concat」の2つだけ。
基本コード
import pandas as pd
import glob
# dataフォルダ内の全Excelファイルを取得
files = glob.glob("data/*.xlsx")
# 全ファイルを読み込んでリスト化
df_list = [pd.read_excel(f) for f in files]
# 1つのDataFrameに結合
result = pd.concat(df_list, ignore_index=True)
# 結果をExcelに出力
result.to_excel("統合データ.xlsx", index=False)
print(f"{len(files)}ファイルを統合しました")コードのポイント
- glob.glob(“data/*.xlsx”):dataフォルダ内のxlsxファイルをすべて取得
- pd.read_excel(f) for f in files:すべてのファイルを読み込んでリスト化
- pd.concat:複数のDataFrameを縦に結合する
- ignore_index=True:インデックスを振り直す(重要)
※ファイルの順番を保証したい場合は sorted(files) でソートしてから処理します。
第5章|応用1|ファイル名を列として追加する
ただ統合しただけでは、「どのファイルから来たデータか」が分からなくなります。ファイル名を新しい列として追加する方法を紹介します。
ファイル名を列に追加するコード
import pandas as pd
import glob
import os
files = glob.glob("data/*.xlsx")
df_list = []
for f in files:
df = pd.read_excel(f)
# ファイル名を新しい列として追加(拡張子なし)
df["ファイル名"] = os.path.splitext(os.path.basename(f))[0]
df_list.append(df)
result = pd.concat(df_list, ignore_index=True)
result.to_excel("統合データ_ファイル名付き.xlsx", index=False)
print("完了しました")解説
- os.path.basename(f):パスから「店舗A_売上.xlsx」のようなファイル名だけを取り出す
- os.path.splitext()[0]:拡張子を除去(「店舗A_売上」になる)
- df[“ファイル名”] = …:新しい列として追加
これで、統合後のデータで「どのファイル由来か」が一目で分かります。
第6章|応用2|複数シートを統合する
1つのExcelファイル内に複数シートがある場合、それらを統合する方法も紹介します。
シナリオ:1ファイル内の複数シートを統合
例:「年間売上.xlsx」に「1月」「2月」「3月」のシートがある場合
import pandas as pd
# シート名を指定せずに全シートを読み込む(dict形式で返る)
sheets = pd.read_excel("年間売上.xlsx", sheet_name=None)
df_list = []
for sheet_name, df in sheets.items():
df["シート名"] = sheet_name
df_list.append(df)
result = pd.concat(df_list, ignore_index=True)
result.to_excel("年間統合.xlsx", index=False)
print("完了しました")解説
- sheet_name=None:すべてのシートを辞書形式で取得
- sheets.items():シート名とデータの組を順に取り出す
- シート名も列として保持できる
複数ファイル × 複数シート
複数ファイルそれぞれに複数シートがある場合は、組み合わせて使います。
import pandas as pd
import glob
import os
files = glob.glob("data/*.xlsx")
df_list = []
for f in files:
file_name = os.path.splitext(os.path.basename(f))[0]
sheets = pd.read_excel(f, sheet_name=None)
for sheet_name, df in sheets.items():
df["ファイル名"] = file_name
df["シート名"] = sheet_name
df_list.append(df)
result = pd.concat(df_list, ignore_index=True)
result.to_excel("完全統合.xlsx", index=False)
print(f"{len(files)}ファイルを統合しました")第7章|実務で使える完成コード
ここまでの内容を統合した、実務でそのまま使える完成コードです。
完成版:複数Excel統合スクリプト
import pandas as pd
import glob
import os
from datetime import datetime
# === 設定 ===
INPUT_FOLDER = "data"
OUTPUT_FILE = f"統合結果_{datetime.now().strftime('%Y%m%d_%H%M')}.xlsx"
# === ファイル取得 ===
files = sorted(glob.glob(f"{INPUT_FOLDER}/*.xlsx"))
if not files:
print(f"{INPUT_FOLDER}フォルダにExcelファイルがありません")
exit()
print(f"{len(files)}ファイルを統合します...")
# === 読み込み・統合 ===
df_list = []
for f in files:
file_name = os.path.splitext(os.path.basename(f))[0]
try:
sheets = pd.read_excel(f, sheet_name=None)
for sheet_name, df in sheets.items():
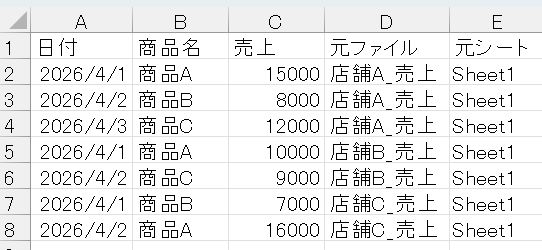
df["元ファイル"] = file_name
df["元シート"] = sheet_name
df_list.append(df)
print(f" ✓ {file_name}")
except Exception as e:
print(f" ✗ {file_name}:エラー({e})")
# === 結合・出力 ===
if df_list:
result = pd.concat(df_list, ignore_index=True)
result.to_excel(OUTPUT_FILE, index=False)
print(f"\n完了:{len(result)}行のデータを{OUTPUT_FILE}に出力しました")
else:
print("読み込めるデータがありませんでした")このコードでできること
- dataフォルダ内のすべてのExcelファイルを自動取得
- 各ファイル内の全シートを統合
- 元のファイル名・シート名を列として保持
- 実行日時付きのファイル名で出力(上書き防止)
- エラーが発生したファイルがあっても処理を継続
第8章|つまずき対処&まとめ
よくあるトラブルと対処法
トラブル1:列名がファイルごとに違う
症状:
統合した結果、空欄が大量に発生する。
対処:
各ファイルの列名を統一してから統合します。
df.columns = ["日付", "商品名", "売上"] # 列名を強制的に統一トラブル2:日付列の形式がバラバラ
対処:
統合後にまとめて日付型に変換します。
result["日付"] = pd.to_datetime(result["日付"])トラブル3:ファイル数が多すぎてメモリ不足
対処:
一度にすべて読み込まず、1ファイルごとに統合先に追記する形にします。CSV形式で出力する方法も有効です。
トラブル4:ヘッダー行がデータの途中にある
対処:
skiprows でヘッダー行をスキップして読み込みます。
df = pd.read_excel(f, skiprows=3) # 最初の3行を飛ばすこの記事のまとめ
- globでフォルダ内のファイルを一括取得
- pd.concatで複数のDataFrameを縦に結合
- ファイル名・シート名を列として保持できる
- 100ファイルが1分で統合可能
- エラー処理を入れることで実務で安心して使える
次に読むべき記事
- 【完全ガイド】非エンジニアのためのPython業務自動化
- 【コピペで使える】pandasで売上データを自動集計する完全マニュアル
- 【完全版】uv入門|Pythonの新標準・最速の環境管理ツール
- 業務レポートの完全自動化マニュアル(公開予定)
FAQ
この記事を書いた人
ソニック|バックオフィス7年目の業務効率化ブロガー。学校事務職員時代に複数ファイル統合の苦労を経験し、現在はデータサイエンス業務に従事。
コメント