

 ソニック
ソニックExcelで半日かかる作業を30秒に短縮
「毎月の売上集計に半日かかる」「ピボットテーブルが重くて固まる」
そんな悩みを、pandas(パンダス)が解決してくれます。
この記事では、pandasを使った売上データの集計方法を、コピペで使えるコード付きで完全解説します。基本のgroupbyから、複数条件・期間別・Excel出力まで、業務でそのまま使えるテクニックを網羅しました。
読み終わる頃には、Excelで半日かかっていた集計作業を30秒で終わらせられるようになります。
第1章|なぜpandasで売上集計するのか
Excelの限界:半日かかる集計が、Pythonでは30秒
私自身、学校事務員として働いていた頃、毎月の集計作業に膨大な時間を費やしていました。複雑なSUMIFを駆使し、ピボットテーブルで集計し、結果をコピペして整える――この一連の作業に、半日以上かかっていたのです。
そんな業務が、pandasを使えば数十秒で完了します。しかも、何度実行しても同じ結果が得られ、ヒューマンエラーもゼロ。
pandasが向いている業務
- 毎月・毎週繰り返す定型集計作業
- Excelでは重くて開けない大量データの処理
- 複数の条件を組み合わせた複雑な集計
- 月次・週次・日次など期間別の集計
- 結果を別のExcelファイルに自動出力する作業
pandasのメリット
| 観点 | Excel | pandas |
|---|---|---|
| 100万行のデータ処理 | 固まる・開けない | 数秒で処理 |
| 再現性 | 毎回手動 | コード実行で完了 |
| ヒューマンエラー | 起こりやすい | 起こらない |
| 複雑な条件集計 | 関数の組み合わせが必要 | シンプルなコードで完了 |
第2章|環境準備(uv環境前提)
この記事は、uv環境でPythonを使う前提で進めます。まだuvをインストールしていない方は、以下の記事を先にご覧ください。

必要なライブラリの追加
プロジェクトフォルダで、以下のコマンドを実行します。
uv add pandas openpyxlpandasとopenpyxlの2つがインストールされれば準備完了です。
※pandasはデータ処理、openpyxlはExcelファイルの読み書きに使います。両方を同時にインストールしておくと安心です。
第3章|サンプルデータの準備
実際にコードを動かすために、サンプルの売上データを用意します。
売上データのCSVを作成する
以下の内容を「売上データ.csv」というファイル名で保存してください。
日付,商品名,店舗,売上
2026-04-01,商品A,東京店,15000
2026-04-01,商品B,東京店,8000
2026-04-01,商品A,大阪店,12000
2026-04-02,商品C,東京店,5000
2026-04-02,商品A,東京店,18000
2026-04-02,商品B,大阪店,9500
2026-04-03,商品C,大阪店,6000
2026-04-03,商品A,東京店,22000
2026-04-04,商品B,東京店,7500
2026-04-04,商品A,大阪店,14000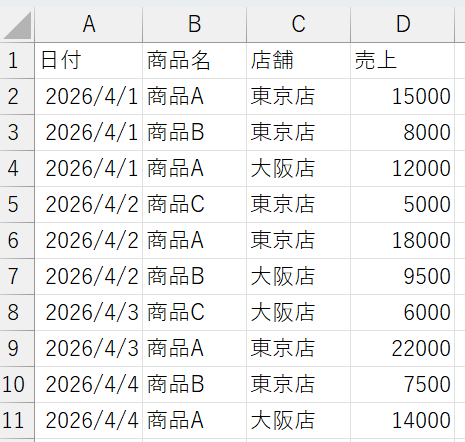
4列構成(日付、商品名、店舗、売上)の売上データです。10行のデータですが、コードは何万行・何百万行のデータでも同じように動きます。
CSVをpandasで読み込む
まずは、CSVを読み込んで中身を確認しましょう。
import pandas as pd
# CSVファイルを読み込む
df = pd.read_csv("売上データ.csv")
# 中身を表示
print(df)実行コマンド:
uv run script.py読み込んだデータが表示されれば成功です。
※日本語ファイル名で文字化けする場合は、encoding=”cp932″ を指定します:pd.read_csv(“売上データ.csv”, encoding=”cp932″)
第4章|基本の集計|groupbyの使い方
pandasの集計の基本は「groupby」です。Excelで言うピボットテーブルに相当する機能で、特定の列でグループ化して集計します。
商品別の売上合計
import pandas as pd
df = pd.read_csv("売上データ.csv")
# 商品別に売上を合計
result = df.groupby("商品名")["売上"].sum()
print(result)実行結果:
商品名 商品A 81000 商品B 25000 商品C 11000 Name: 売上, dtype: int64たった3行のコードで、商品別の売上集計が完了します。
groupbyの仕組み
groupbyは「グループ化したい列」と「集計したい列」を指定するだけで使えます。
- df.groupby(“商品名”):「商品名」でグループ化
- [“売上”]:「売上」列を対象にする
- .sum():合計を計算
様々な集計方法
sum()以外にも、様々な集計関数があります。
| 関数 | 意味 | Excelで言うと |
|---|---|---|
| .sum() | 合計 | SUMIF |
| .mean() | 平均 | AVERAGEIF |
| .count() | 件数 | COUNTIF |
| .max() / .min() | 最大値 / 最小値 | MAX / MIN |
| .median() | 中央値 | MEDIAN |
店舗別の売上集計
グループ化する列を変えるだけで、別の切り口で集計できます。
# 店舗別に売上を合計
result = df.groupby("店舗")["売上"].sum()
print(result)実行結果:
店舗 大阪店 41500 東京店 75500 Name: 売上, dtype: int64第5章|応用1|複数条件での集計
業務では「商品×店舗」「日付×商品」のように、複数の条件を組み合わせた集計が必要になることがほとんどです。pandasではgroupbyに複数の列を渡すだけで実現できます。
商品×店舗で集計
# 商品×店舗で売上を集計
result = df.groupby(["商品名", "店舗"])["売上"].sum()
print(result)実行結果:
商品名 店舗 商品A 大阪店 26000 東京店 55000 商品B 大阪店 9500 東京店 15500 商品C 大阪店 6000 東京店 5000 Name: 売上, dtype: int64これだけで、商品×店舗のクロス集計が完了します。Excelのピボットテーブルと同じことが、たった1行で実現できます。
複数の集計を同時に行う
合計だけでなく、平均・件数も同時に出したい場合は、agg() を使います。
# 合計・平均・件数を同時に計算
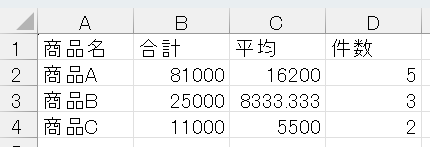
result = df.groupby("商品名")["売上"].agg(["sum", "mean", "count"])
print(result)実行結果:
sum mean count 商品名 商品A 81000 16200.0 5 商品B 25000 8333.3 3 商品C 11000 5500.0 21回の実行で、3つの指標を同時に出せます。
第6章|応用2|期間別の集計
「月別の売上推移」「週別の傾向」など、期間別の集計は業務でよく使います。
日付列を日付型に変換する
CSVから読み込んだ日付は、最初は文字列として扱われます。日付型に変換することで、期間別の集計ができるようになります。
# 「日付」列を日付型に変換
df["日付"] = pd.to_datetime(df["日付"])月別の売上集計
# 日付列をindexに設定して月別に集計
df["日付"] = pd.to_datetime(df["日付"])
result = df.groupby(df["日付"].dt.month)["売上"].sum()
print(result)実行結果:
日付 4 117000 Name: 売上, dtype: int64dt.month で月、dt.year で年、dt.day で日を取得できます。これらを組み合わせれば、年月別・週別など様々な集計が可能です。
週別の集計
# 週別に集計
df["日付"] = pd.to_datetime(df["日付"])
result = df.groupby(pd.Grouper(key="日付", freq="W"))["売上"].sum()
print(result)Grouper を使うと、週・月・四半期など柔軟に期間を指定できます。
| freq指定 | 意味 |
|---|---|
| “D” | 日別 |
| “W” | 週別(日曜終わり) |
| “M” | 月別 |
| “Q” | 四半期別 |
| “Y” | 年別 |
第7章|応用3|結果をExcelファイルに自動出力
集計結果をExcelファイルに保存して、上司や顧客に共有できる状態にします。
シンプルなExcel出力
import pandas as pd
df = pd.read_csv("売上データ.csv")
# 商品別に集計
result = df.groupby("商品名")["売上"].sum()
# Excelに出力
result.to_excel("商品別売上.xlsx")
print("Excelファイルを作成しました")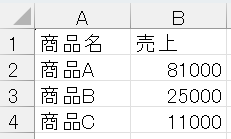
複数のシートに分けて出力
複数の集計結果を、1つのExcelファイルの異なるシートに保存することもできます。
import pandas as pd
df = pd.read_csv("売上データ.csv")
# 各種集計
by_product = df.groupby("商品名")["売上"].sum()
by_store = df.groupby("店舗")["売上"].sum()
by_product_store = df.groupby(["商品名", "店舗"])["売上"].sum()
# 1つのExcelファイルに複数シートで出力
with pd.ExcelWriter("売上集計.xlsx") as writer:
by_product.to_excel(writer, sheet_name="商品別")
by_store.to_excel(writer, sheet_name="店舗別")
by_product_store.to_excel(writer, sheet_name="商品×店舗")
print("売上集計.xlsxを作成しました(3シート)")これで、商品別・店舗別・クロス集計の3つの結果が、1つのExcelファイルにまとめて保存されます。
第8章|実務で使える完成コード
ここまでの内容をまとめた、実務でそのまま使える完成コードです。コピペして、ファイル名や列名を自分の業務に合わせて調整してください。
売上自動集計スクリプト(完成版)
import pandas as pd
from datetime import datetime
# === 設定 ===
INPUT_FILE = "売上データ.csv"
OUTPUT_FILE = f"売上集計_{datetime.now().strftime('%Y%m%d')}.xlsx"
# === データ読み込み ===
df = pd.read_csv(INPUT_FILE, encoding="utf-8")
df["日付"] = pd.to_datetime(df["日付"])
# === 各種集計 ===
# 商品別
by_product = df.groupby("商品名")["売上"].agg(["sum", "mean", "count"])
by_product.columns = ["合計", "平均", "件数"]
# 店舗別
by_store = df.groupby("店舗")["売上"].agg(["sum", "mean", "count"])
by_store.columns = ["合計", "平均", "件数"]
# 商品×店舗
by_product_store = df.groupby(["商品名", "店舗"])["売上"].sum()
# 日別
by_date = df.groupby(df["日付"].dt.date)["売上"].sum()
# === Excelに出力 ===
with pd.ExcelWriter(OUTPUT_FILE) as writer:
by_product.to_excel(writer, sheet_name="商品別")
by_store.to_excel(writer, sheet_name="店舗別")
by_product_store.to_excel(writer, sheet_name="商品×店舗")
by_date.to_excel(writer, sheet_name="日別")
print(f"集計完了:{OUTPUT_FILE}")このコードでできること
- 売上データを商品別・店舗別・商品×店舗・日別の4軸で集計
- 各軸ごとに合計・平均・件数の3指標を算出
- 結果を実行日付付きのExcelファイルに自動保存
- ファイル名に日付が入るので、毎日実行しても上書きされない
第9章|つまずきやすいポイントと対処法
pandasで売上集計をする際に、よくある5つのトラブルと対処法を紹介します。
つまずき1:日本語ファイルの文字化け
症状:
CSVを読み込むと、日本語が「縺薙s縺ォ縺。縺ッ」のように文字化けする。
対処:
encoding=”cp932″ を指定して読み込みます。
df = pd.read_csv("売上データ.csv", encoding="cp932")つまずき2:日付がうまく扱えない
症状:
dt.month や Grouper を使おうとするとエラーが出る。
対処:
日付列を pd.to_datetime() で日付型に変換してから使います。
df["日付"] = pd.to_datetime(df["日付"])つまずき3:列名にスペースや全角が含まれる
症状:
groupby(“商品 名”) のように指定したらKeyErrorが出る。
対処:
df.columns で実際の列名を確認します。先頭や末尾にスペースが入っている場合があります。
print(df.columns)
# 必要なら列名を整形
df.columns = df.columns.str.strip()つまずき4:合計値が小数点で表示される
症状:
整数のはずが「15000.0」のように小数で表示される。
対処:
astype(int) で整数型に変換します。
result = df.groupby("商品名")["売上"].sum().astype(int)つまずき5:データが多すぎてメモリ不足
症状:
数百万行のCSVを読み込むとPCが固まる。
対処:
usecols で必要な列だけ読み込むか、chunksize で分割読み込みします。
# 必要な列だけ読み込む
df = pd.read_csv("売上データ.csv", usecols=["日付", "商品名", "売上"])
# 大量データは分割読み込み
for chunk in pd.read_csv("巨大データ.csv", chunksize=10000):
# 1万行ずつ処理
pass第10章|まとめ&次のステップ
この記事のまとめ
- groupbyを使えば、Excelのピボットテーブルと同じことが1行で実現できる
- 複数列のグループ化、複数指標の集計も簡単に組み合わせられる
- 日付列はpd.to_datetime()で変換することで期間別集計が可能
- ExcelWriterを使えば、複数シートに集計結果を保存できる
- 半日かかる集計作業を、コード10行で30秒に短縮できる
次に読むべき記事
売上集計ができるようになったあなたへ、次のステップとなる記事を紹介します。
- 【完全ガイド】非エンジニアのためのPython業務自動化|業務自動化の全体像を知りたい方に
- 【完全版】uv入門|Pythonの新標準・最速の環境管理ツール|環境構築からやり直したい方に
- 複数Excelファイルを1つに統合するPythonコード|ファイル統合をしたい方に(公開予定)
- 業務レポートの完全自動化マニュアル|定期レポートを自動化したい方に(公開予定)
FAQ|よくある質問
さあ、業務効率化を始めよう
pandasによる売上集計は、Python業務自動化の入り口にすぎません。これができるようになれば、複数ファイルの統合、レポートの自動生成、データの可視化と、可能性は無限に広がります。
「Excelで半日かかっていた作業が、Pythonでは30秒で終わる」――その瞬間の感動を、ぜひ体験してください。
最新の解説記事は、新着記事から順次公開しています。X(旧Twitter)でも更新情報を発信していますので、ぜひフォローしてください。
この記事を書いた人
ソニック|バックオフィス7年目の業務効率化ブロガー。学校事務職員→営業事務→データサイエンス業務へとキャリアを進め、現場で得たノウハウを発信中。
コメント